
This post (after, let’s face it, a massive break) is the written version of a talk by Andrew Weatherall for the Aeromedical Society of Australasia Conference 2019, held in Perth.
This is a thing that’s about blood. And the roadside. And the lab bench. Naturally it starts with a story because clinical research should start with a patient. That’s why we do it. It’s a really topic to talk about because the management of transfusion, and the questions it brings up might seem simple at first glance. But a transfusion in the prehospital environment is a particular example of people across a whole system working for a patient.
And the questions clinicians ask that start with something small are the sorts of questions that make a difference in simple ways to every single patient.
A Mountain Story
You have to cast yourself back to the late 90s. Back when the millennium bug was a spooky tale and not an impressively well managed systems vulnerability.
On a particular morning back then there was a car accident in the Blue Mountains, just outside of Sydney. It was serious. The driver had died.
These were the times when asking for a team with a few more options waited until the ambulance officers had got to the scene and started working very hard. So around 28 minutes after the accident, the CareFlight crew on that day got a call to attend to try and help a passenger. Around 52 minutes had passed by the time they reached the patient.
In that time a lot of difficult treatment and rescue work had already happened. The patient, a 15 year old was accessible but still a bit stuck. The paramedics had already started care. In this case this included a large bore cannulae and 6 litres of polygeline fluid resuscitation.
I should have mentioned it was 7 degrees Celsius this particular morning.
Over the course of the extrication all the crews on scene combined. The patient was intubated because the combination of their injuries, diminishing conscious level and the respiratory rate of 40/min suggested something was up.
They received the 4 units of red cells that the CareFlight crew was carrying. The heart rate of 140/min and blood pressure of 70 mmHg made it clear bleeding was an issue. It was an issue that needed more red cells. How does that happen on a cold day in the mountains in 1997? The local hospital, nothing like a trauma hospital sends O negative red cells when they receive a call. The police deliver it.
The patient had a chest drain inserted after their breath sounds changed unilaterally.
But it was clear they needed more fluid resuscitation. And more.
In total, by the time the patient reached their destination hospital a flight later and about 132 minutes after their injury, the combined teams had managed to find a total of 15 units for that patient. Which gave the hospital a chance to get working.
The receiving hospital that day was Nepean hospital, at the foot of the mountains (and these days not a major trauma centre). They received a critically unwell patient and had a long day in the operating theatres. A long day with a long list of injuries who received a further 56 units of red cells, 16 units of platelets and 19 units of FFP.
And survived.
I know they survived because they provided consent for the first case report of massive transfusion in the prehospital setting that Rob Bartolacci and Alan Garner wrote up in the MJA in 1999.
Questions
That story could be seen as an extraordinary success. It didn’t stop the crew asking questions though. This was of course before we knew nearly as much about trauma and bleeding and coagulopathy. I mean we knew it was an issue but Brohi et al hadn’t published that excellent work showing a rate of coagulopathy of 24.4% or the huge import of coagulopathy when it came to mortality.
We didn’t have nearly as much understanding of the ills of acidosis, coagulopathy and hypothermia. We didn’t even have as much evidence about how easy it is to cool patients with cooled fluids as we now do.
We knew hypothermia was bad though. So when that patient arrived to hospital with a temperature of 29.5 degrees Celsius and a heart rate of 80/min, the crew started thinking about ways to do it better.
These days of course we prioritise haemorrhage control. We have a different approach to administering massive transfusions. We’d be reaching for tranexamic acid. Along the way though the first question was ‘how do we try and make our fluids warm?’ Red cells come out of the esky at around 4 degrees Celsius. Patients are not designed to meet that temperature halfway.
Lots of things have been tried over the years. In the past we’d relied on the Australian sun. We’d relied on the toasty armpit of an emergency service worker probably wearing a non-breathable fabric blend that isn’t very flattering to the profile. We’d tried gel heat pads that you’d use to ease a muscle ache.
Fast forward a decade and a bit though and we finally had a portable fluid warming device small enough to help us out. We felt pretty good about the Belmont Buddy Lite too. It was a huge step up, we figured, from what we’d been doing.
Clinicians still ask questions though. This time it was another CareFlight specialist, James Milligan, who started asking questions. It was a pretty simple one really. ‘Maybe we should check how much better it is than all the other options we’ve tried?’
Simple, right?
Setting the Right Rules
Now one of the great challenges when you’re trying to do bench testing of a device for prehospital and retrieval medicine is getting the balance right. You want to produce measurements that are rigorous and reliable enough to give you real information. The risk when you do that is that you do things so differently to the environment that counts for us that it no longer represents something that still applies at the roadside.
So the natural choice if you want to bench test a prehospital blood warming device is this …

… a bespoke cardiopulmonary bypass circuit to deliver reliable flows, measure the temperature at multiple sites, measure pressure changes across the circuit, collect the first unit of red cells you administer, spin it down and cool it then recirculate that blood to deliver the equivalent of a second unit.
With a plan to fix the flow rates to 50 mL/min (the suggested rate for the Buddy Lite), randomise the sequence of runs and repeat each type of run 3 times to generate useful data. We standardised as much as we could, including the spine board we used for the ‘on a warmed spine board in the sun’ group and had the board heating for a standardised period of time. We used a single armpit to generate body heating. (Yes, I can confirm that sometimes you have to sacrifice a few frozen off armpit hairs for science.) You get those gel pads ready to go. You get the support in an entirely different setting from your blood bank.
Then it’s time to test how MacGyver works in real life.
Phase 1: A Warmer vs MacGyver.
This study turned out to be one of those ones where the results match pretty much what you thought. You can find the full paper here but the key table to pull out is this one.

Even with this simple study there are a few interesting points to note:
- There is actually more warming than you might expect when you just run the fluid through an intravenous fluid line.
- The Australian sun actually did pretty well.
- My armpit is just an embarrassment. Only for this reason.
- Gel pads just don’t have the contact time to count.
- The thing specifically designed for warming turns out to be better than warming.
Phew. Done and dusted.
Except we had more questions.
The thing is as clinicians we knew that delivering at 50 mL/min is probably not what we do when a patient is really critically unwell. There’s every chance it’s quicker. It certainly was in 1997. Maybe even pulsed because someone is squeezing it in.
So to really make the benchtop more like the place we work, we wanted to test different flow rates. We also thought maybe we should double check that putting red cells through a rapid temperature change across a small area of space where at least some pressure changes happen inside the device was still OK for red cells. What if we haemolyse a bunch of hose bendy little discs.
Happily just as we got there, more devices hit the market.
Phase 2: Warmer vs Warmer
We had some more limits to set though. The devices we’re after for prehospital work need to be light enough to not be too annoying. They have to be free of an external power source. Ideally they’d be idiot proof. I mean folks like me just a little overloaded at the accident scene need to use them.
So we looked for devices that could do the job at a total weight under 1 kg and that operated as standalone units. We ended up with 4 to test:
- The Thermal Angel.
- The M0
- The Hypotherm X LG.
- The Buddy Lite.
This time with flow rates of 50 mL/min, 100 mL/min, and 200 mL/min (the maximum rating of any device was 150 mL/min but we also knew that with a pump set we can get up as high as those numbers). Still randomised. This time with fresh units of red cells so we could test for haemolysis on the first run through the circuit.
The testing circuit was a little different this time, mostly because it did things better and would reliably deliver the flow rate all the way to 200 mL/min. It was a bit quicker to cool the units too.
The results this time are best shown in a couple of the tables. At 50 mL/min there’s one warmer that’s clearly performing better than the others. The red cells reach the thermistor that reflects delivery to the patient at 36.60C. The best of the others only gets to 30.50C.

When you get to higher flow rates the difference is even more marked.

That same device gets the blood to 32.50C. The others? 23.7, 23.5 and 19.40C.
That is a heck of a difference.
Along the way we couldn’t pick up any evidence of haemolysis. We count that as the best sort of negative result.
Oh, that warmer was the M warmer. We switched.
The Deeper Bits
A study that started with a very simple question ended up being a pretty fun excursion into the lab. Except for that one thing where the clamp went on the wrong bit of the circuit.
For no reason at all I’m just going to mention that wearing PPE not your own clothes is something you should be glad you do at work. It pays off.
The other thing worth noting is that all of these devices go through a process before they become available for sale commercially. That is part of what the TGA does. And they all do kind of what they say on the box. They do warm things up. They are unlikely to cause problems. They’re not the same though. You could even argue that some of them performed so below the level of the most effective device we tested that it’s only marginally better than our next reference, my armpit.
Everything that goes to market has its own story, just like the little pig who goes to market I guess. The TGA is obviously very rigorous in applying its incredibly voluminous guidelines. And I wouldn’t suggest that the manufacturers or those sponsoring the devices t get into the market haven’t likewise followed every part of that process.
What is less clear to me is how you demonstrate ‘suitable for intended use’ which is one of the essential principles that must be shown to be met. Near as we can tell there wasn’t prior testing of these units that so rigorously reflected how we’re likely to use the units in our actual practice prehospitally.
There is a requirement to show that the design meets appropriate standards and that there is clinical evidence. However you are permitted to show that testing is similar enough to the area you reckon it can be used that it gets signed off. On my read of the guidelines you can even show good evidence for the principle of blood warming and that a similar device has been shown to do that well and say ‘our tech specs show we can do the same thing so tick here please’. Extrapolating practice from the hospital or other settings to prehospital and retrieval medicine is a thing we often have to do but that doesn’t mean we should just accept that.
So when you look at a design like, say, the Buddy Lite (a device that has served us really well and that was a huge step up from what we were doing) you can see that it would meet lots of essential principles about not exposing the patient to harm, being safe to handle and operate and warming the infusate. As long as it is delivered as suggested by the manufacturer at 50 mL/min.
And that’s the bit of evaluation that we can’t rely on the TGA to do for us. Is 50 mL/min what we’re after?
We need clinicians asking questions.
Slow Down
So we started with a question. Actually the questions have been happening since at least the 90s.
Simple questions asked by clinicians thinking about the patient in front of them are really useful. They take you in unexpected directions. They lead you to work in teams just like you do at the accident scene. It’s just that this team involves some doctors and a paediatric perfusionist and a haematologist and a lab technician and the blood bank and the Red Cross and a statistician in Hong Kong.
And we’ll keep asking questions. Along the way on this study we figured out that the Hypotherm was just a little challenging to use. In using the M warmer we’ve picked up ways we need to manage the battery recharging.
Clinical teams are vital to doing things better for our patients not just because we actually do the doing, but because the studies that get out there need to be interpreted by people who know the operating space. Or it needs to be clinical teams and patients inspiring studies in the first place.
Someone needs to keep an eye on the pigs when they’re trying to get to market.

The References Bit:
OK that’s quite long.
That case report is this one (and obviously the patient has given permission for its use in contexts like this):
The first of the blood warming papers is this one:
The more recent one comparing devices is this one:
If you want to read that Brohi et al paper again it’s here:
Brohi K, Singh J, Heron M, Coats T. Acute traumatic coagulopathy. J Trauma. 2003;54:1127-30.
You might like to reflect on just how quickly you can cool someone down with cold crystalloid:
If you have lots of spare time you might like to read the TGA regulations. (Note they are being updated.) I advise drinking coffee first.
And did you get all this way? Then you definitely need to watch this and relax.
 If you start with a clean slate and optimally position bases for either population coverage or average response time, both models place bases to cover that part of the coast (see Figure 2). Hardly surprising. When we modelled to optimise the existing base structure by adding or moving one or two bases, the mid north coast was either first or second location chosen by either model too.
If you start with a clean slate and optimally position bases for either population coverage or average response time, both models place bases to cover that part of the coast (see Figure 2). Hardly surprising. When we modelled to optimise the existing base structure by adding or moving one or two bases, the mid north coast was either first or second location chosen by either model too.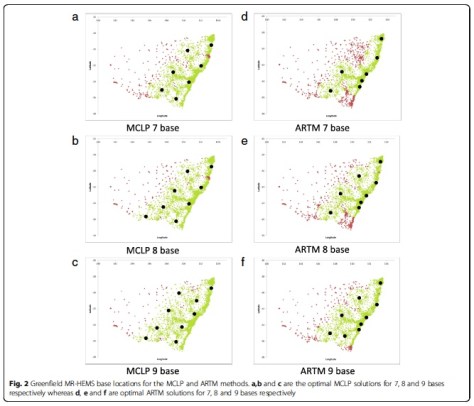





![Early engineering advice included "just put a tinfoil hat on everyone to shield the sensors". I just ... I ... can't ... [via eclipse_etc at Flickr 'The Commons']](https://careflightcollective.com/wp-content/uploads/2015/06/tin-eclipse_etc.jpg)
![Maybe this much salt. [via user pee vee at Flickr's 'The Commons']](https://careflightcollective.com/wp-content/uploads/2015/06/salt-pee-vee-copy.jpg)
![Yes Sclater's lemur, that's 16 monitoring values to keep track of. [via user Tambako the Jaguar at flickr]](https://careflightcollective.com/wp-content/uploads/2015/06/sclaters-lemur-tambako-the-jaguar-copy.jpg)

![See? Here's the pretty version that comes with the monitor we're using in the study? [It's the Nonin EQUANOX and we bought it outright.]](https://careflightcollective.com/wp-content/uploads/2015/05/sensor-copy.jpg)
![Maybe that's harsh. Could a walrus be anything but elegant? [via Allan Hopkins on flickr under CC 2.0]](https://careflightcollective.com/wp-content/uploads/2015/05/walrus-copy.jpg)
![This is from an excellent review by Elwell and Cooper. [Elwell CE, Cooper CE. Making light work: illuminating the future of biomedical optics. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences. 2011;369:4358-4379.]](https://careflightcollective.com/wp-content/uploads/2015/05/the-equation-copy.jpg)



![Getting to a CT scanner in a more timely fashion than this was a way of tracking patient progress through their care. [via telegraph.co.uk]](https://careflightcollective.com/wp-content/uploads/2015/03/mummy-copy.jpg)


